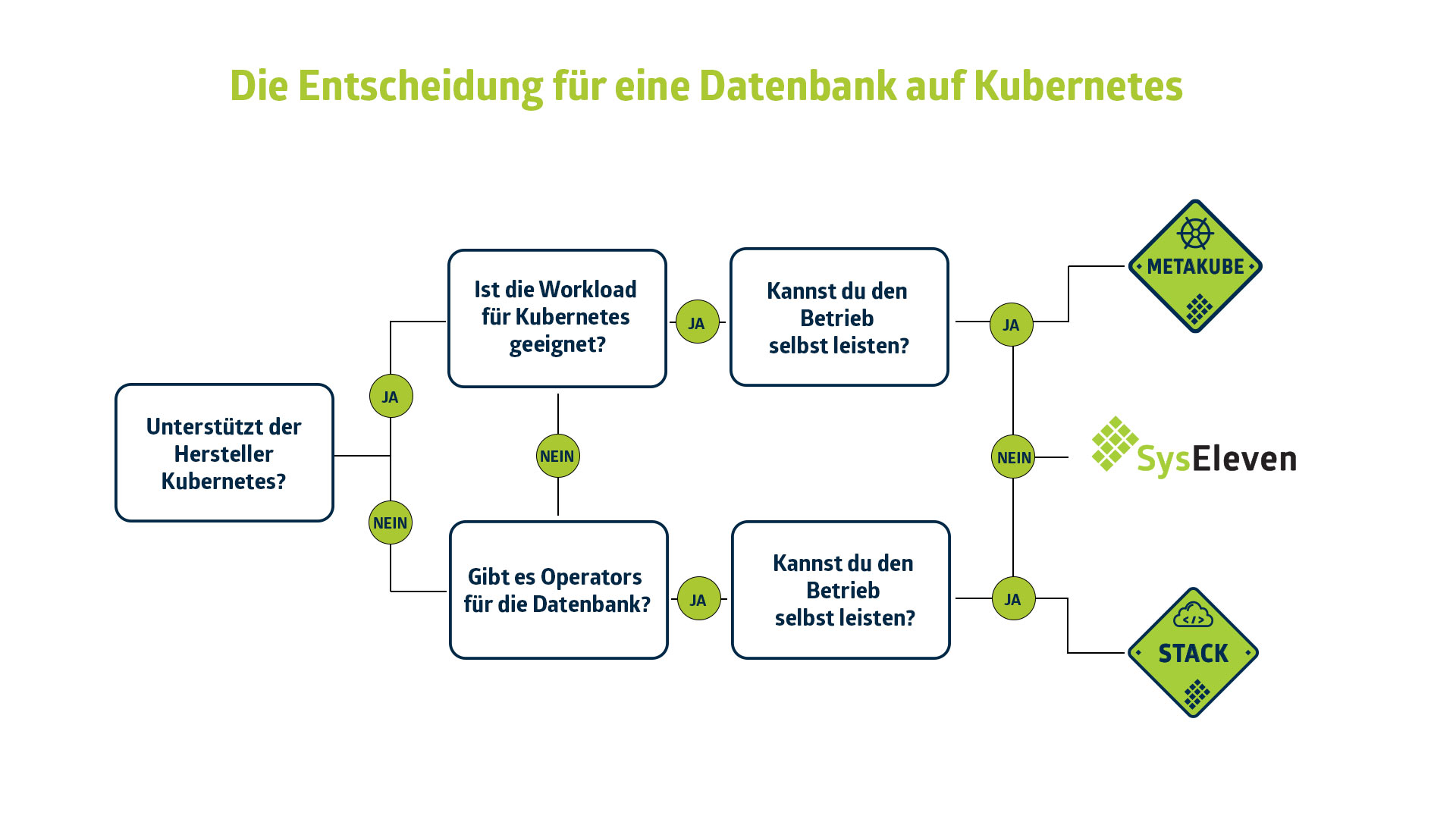
Das Ops in DevOps
Der letzte und wichtigste Punkt ist die Aufgabe der Langzeitspeicherung und des damit einhergehenden Betriebs. Darunter fallen auch Backup-Mechanismen. Das sind Tätigkeiten, die regelmäßig geprüft und nicht vernachlässigt werden dürfen. Sei es nun Velero als eigenständige Backup-Komponente oder ein Kubernetes-Job zur Erzeugung eines Datenbank-Dumps – auch für diesen Bereich gibt es Methoden, die abseits des restlichen Systems die Arbeit vereinfachen.
Damit werden die Daten auch außerhalb eures Kubernetes-Clusters gesichert. Diese Automatisierungen ermöglichen es euch, die Langzeitspeicherung da zu betreiben, wo es für euch am günstigsten ist. Ein Datenbank-Dump kann verschlüsselt auch gut in einem S3-kompatiblen Speicher abgelegt werden.
Mit der verteilten Herangehensweise – In-Memory-Datenbanken, persistente Datenbanken als Cluster und zusätzliche Tools für Langzeitspeicherung – kreieren wir aus einem Datenbank-Layer drei neue. Ausfallzeiten werden dadurch weiter reduziert. Die Komplexität im Umfeld der Containerisierung steigt aber weiterhin.
Der Blog-Beitrag “Service Mesh” gibt bereits eine Möglichkeit des Managements an die Hand. Darüber hinaus werden wir im nächsten Artikel mit “Continuous Integration & Delivery” erklären, wie diese Art von Einstellungen auf Kubernetes zu standardisierten Prozessen für beliebig viele Setups führen kann.
Egal, wie Du Dich entscheidest: Wir helfen Dir bei jeder Art von Setup.