….aber zur gleichen Zeit 324 TB der selben Datei runterladen?
- Oder auch „wie du dich durch viele Layer von Technolgie täuschen lassen kannst“.
- Oder auch „Wieso man selbst in vollständig automatisierten Setups Menschen braucht, die Systeme warten und Problem debuggen“.
- Oder auch „Was machst Du eigentlich den ganzen Tag (als SysAdmin)?“.
In diesem Artikel wird über HTTP Status Codes geschrieben ohne diese immer explizit zu erklären. Ein Hintergrund in HTTP Status Codes wäre als Hintergrundwissen also gut zu haben 🙂
Inhaltsverzeichnis
Die Situation
Vor ein paar Tagen kam eine Kollegin zu mir und fragte mich, wieso sie nicht das neuste RedHat 8.4 ISO von unseren Kubernetes-basierten Downloadservern runterladen kann.
Andere ältere Dateien (mit einer groben ~700MB Dateigröße) ließen sich jedoch weiterhin ohne Probleme runterladen.
Problembeschreibung
Beim Runterladen der Datei sah es so aus:
❯ wget -c http://downloads.example.com/rhel84.iso
--2021-11-09 14:53:13-- http://downloads.example.com/rhel84.iso
Resolving downloads.example.com (downloads.example.com)... $PUBLIC_IP
Connecting to downloads.example.com (downloads.example.com)|$PUBLIC_IP|:80... connected.
HTTP request sent, awaiting response... 206 Partial Content
Length: 9425010908 (8,8G), 9403307812 (8,8G) remaining [application/octet-stream]
Saving to: ‘rhel84.iso’
rhel84.iso 0%[> ] 83,86M 4,34MB/s in 14s
2021-11-09 14:53:28 (4,36 MB/s) - Connection closed at byte 87928842. Retrying.
--2021-11-09 14:53:29-- (try: 2) http://downloads.example.com/rhel84.iso
Connecting to downloads.example.com (downloads.example.com)|$PUBLIC_IP|:80... connected.
HTTP request sent, awaiting response... 416 Requested Range Not Satisfiable
The file is already fully retrieved; nothing to do.
Das ist alles irgendwie ziemlich seltsam.
- Wieso liefert der NginX beim ersten Request ein 206 Partial Content anstelle eines 200 Ok aus? Es wurde das ganze File angefragt und nicht nur ein Teil davon.
- Wieso wird die Connection closed nach 87928842 bytes?
- Wieso setzt es beim Retry nicht mit einem tatsächlichen 206 Partial Content fort, sondern liefert stattdessen einen 416 Requested Range Not Satisfiable?!
- Und zu allerletzt… was bedeutet bitte: The file is already fully retrieved; nothing to do.? Die 10 GB sind definitiv noch nicht fertig runtergeladen.
Mehrfaches wget Ausführen hat bei jedem einzelnen Ausführen immer andere Resultate geliefert. Jedes mal ist es scheinbar bei zufälligen Byte Counts und mit anderen HTTP codes abgebrochen.
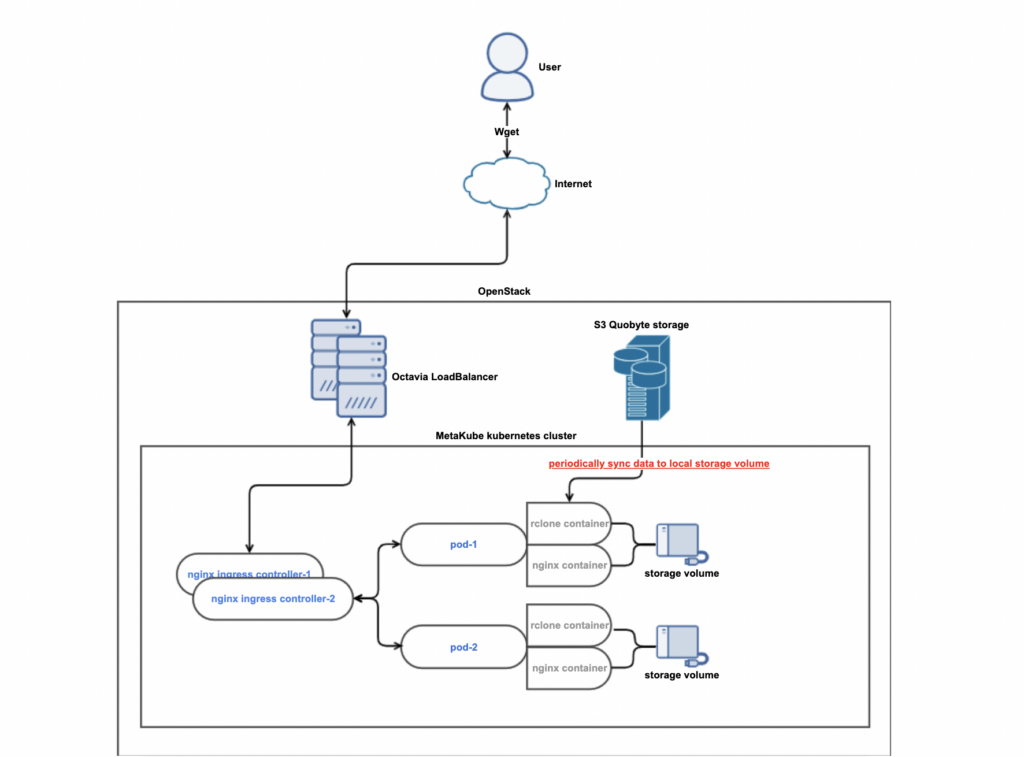
Architektur des Downloadservers
Für ein Kubernetes-Setup ist der Downloadserver ziemlich „simple/klassisch“ mit folgenden Komponenten:
- Octavia LBaaS
- NginX Ingress Controller
- Mehrere Pods mit jeweils 2 Containern
- Statischer NginX
- Liefert lokale Files aus via
root /path/to/data;
- Liefert lokale Files aus via
RClone Container- Synced S3-Files von einem S3-Bucket in ein lokales Persistent Volume an jedem einzelnen Pod
- Statischer NginX
Mehr Debugging
Logs
Nun, starten wir mit mal, indem wir in die Logs vom NginX-Container unseres Pods und unseres Ingress-Controllers reinschauen:
## ingress-controller
"2021/11/09 14:05:31 [error] 44#44: *25643 upstream prematurely closed connection while sending to client, client: 172.25.1.0, server: downloads.example.com, request: \"GET /rhel84.iso HTTP/1.1\", upstream: \"http://172.25.2.140:80/rhel84.iso\", host: \"downloads.example.com\"\n"
## Pod nginx
2021/11/09 13:54:26 [alert] 6#0: *159 sendfile() reported that "/data/rhel84.iso" was truncated at 189547564 while sending response to client, client: 172.25.4.64, server: , request: "GET /rhel84.iso HTTP/1.1", host: "downloads.example.com"
NGINX Probleme
Da ich zur $search-engine Generation gehöre, suchte ich also zu allererst mal nach Upstream-Bugs für NginX und großen Dateien.
So unfassbar wie mein Glück zu sein scheint gab es ein sehr sehr sehr vielversprechendes NginX Bug-Ticket: Large file download is not completed with sendfile option.
Geöffnet vor 2 Jahren
Geschlossen vor 12 Tagen!
Dieser Zufall, dass es tatächlich genau dieses eine exakte Problem mit einem 2 Jahre alten Bug-Ticket existiert, welches wirklich erst vor 12 Tagen erfolgreich gelöst und geschlossen worden sein soll, ist unvorstellbar.
ES GAB SOGAR EIN RELEASE MIT DEM FIX! https://nginx.org/en/CHANGES
Changes with nginx 1.21.4 02 Nov 2021
*) Change: the default value of the "sendfile_max_chunk" directive was
changed to 2 megabytes.
Nachdem meine Kollegin nun also die NginX-Version im Docker-Image upgedatet und in der Stage-Umgebung ausgerollt hat… passiert genau nichts anderes als vorher. Der Download war immer noch willkürlich kaputt.
sendfile() und proxy_buffers
Nun, wir haben diverseste Varianten von Werten von disable/enable für sendfile() und verschiedene Größen von proxy_buffers für Ingress-Controller probiert. Das hat alles jedoch gar keinen Unterschied gemacht. Außer, dass wir immer gehofft haben, dass es geholfen hat und dann aber enttäuscht waren, weil es einfach wirklich willkürlich kaputt ist… mal mehr und mal weniger ![]()
Nach mehr Hilfe fragen
Yay pair programming
Um der Sache nun noch tiefer nachzugehen, habe ich nun mit einem weiteren Kollegen gepaired.

root@deployment-pvc:/mnt# wget --header 'Host: downloads-stage.example.com' http://10.10.10.68/rhel84.iso
--2021-11-10 14:15:55-- http://10.10.10.68/rhel84.iso
Connecting to 10.10.10.68:80... connected.
HTTP request sent, awaiting response... 200 OK
Length: 10130292736 (9.4G) [application/octet-stream]
Saving to: 'rhel84.iso.6'
rhel84.iso.6 28%[===============> ] 2.70G 113MB/s in 33s
2021-11-10 14:16:28 (83.8 MB/s) - Connection closed at byte 2894528512. Retrying.
Okay, das ist kaputt. Weiter.
root@deployment-pvc:/mnt# wget http://downloads-svc/rhel84.iso
--2021-11-10 14:17:23-- http://downloads-svc/rhel84.iso
Resolving downloads-svc (downloads-svc)... 10.10.10.82
Connecting to downloads-svc (downloads-svc)|10.10.10.82|:80... connected.
HTTP request sent, awaiting response... 200 OK
Length: 7801600344 (7.3G) [application/octet-stream]
Saving to: 'rhel84.iso.7'
rhel84.iso.7 5%[==> ] 397.52M 49.0MB/s in 17s
2021-11-10 14:17:40 (23.8 MB/s) - Connection closed at byte 416834404. Retrying.
Okay, das ist auch kaputt. Weiter.
root@deployment-pvc:/mnt# wget http://172.25.2.108/rhel84.iso
--2021-11-10 14:18:16-- http://172.25.2.108/rhel84.iso
Connecting to 172.25.2.108:80... connected.
HTTP request sent, awaiting response... 200 OK
Length: 9527521280 (8.9G) [application/octet-stream]
Saving to: 'rhel84.iso.8'
rhel84.iso.8 86%[================================================> ] 7.69G 68.5MB/s in 42s
2021-11-10 14:18:57 (189 MB/s) - Connection closed at byte 8254390272. Retrying.
--2021-11-10 14:18:58-- (try: 2) http://172.25.2.108/rhel84.iso
Connecting to 172.25.2.108:80... connected.
HTTP request sent, awaiting response... 416 Requested Range Not Satisfiable
The file is already fully retrieved; nothing to do.
Okay, das ist immer noch schlecht… also… das muss ein NginX-Problem sein, oder? CPU-Probleme?
Ich erinnere mich, wir hatten am Anfang mit Kubernetes Probleme bei CPU-Limits an unseren NginX pods, vielleicht ist das hier auch ein Problem? Okay, das Entfernen der CPU-limits scheint auch leider nicht zu helfen. :/
rclone verstehen und lernen
Moooment, wieso benutzt der rclone-Container eigentlich dauerhaft 3-4 CPUs die gesamte Zeit?
Beim Blick in die Logs ist sogar zu erkennen, dass es dauerhaft Fehler dieser Art wirft:
2021-11-10 09:36:07
{"log":"2021/11/10 08:36:07 Failed to copy with 3 errors: last error was: multipart copy: read failed: unexpected EOF\n","stream":"stdout","time":"2021-11-10T08:36:07.337041391Z"}
2021-11-10 09:36:07
{"log":"\n","stream":"stdout","time":"2021-11-10T08:36:07.337037452Z"}
2021-11-10 09:36:07
{"log":"Elapsed time: 16m3.3s\n","stream":"stdout","time":"2021-11-10T08:36:07.337033359Z"}
2021-11-10 09:36:07
{"log":"Checks: 39 / 39, 100%\n","stream":"stdout","time":"2021-11-10T08:36:07.337029175Z"}
2021-11-10 09:36:07
{"log":"Errors: 3 (retrying may help)\n","stream":"stdout","time":"2021-11-10T08:36:07.337025074Z"}
2021-11-10 09:36:07
{"log":"Transferred: \u0009 284.714Gi / 284.714 GiByte, 100%, 243.294 MiByte/s, ETA 0s\n","stream":"stdout","time":"2021-11-10T08:36:07.337020309Z"}
2021-11-10 09:36:07
{"log":"2021/11/10 08:36:07 INFO : \n","stream":"stdout","time":"2021-11-10T08:36:07.337015994Z"}
2021-11-10 09:36:07
{"log":"2021/11/10 08:36:07 ERROR : Attempt 3/3 failed with 3 errors and: multipart copy: read failed: unexpected EOF\n","stream":"stdout","time":"2021-11-10T08:36:07.337009789Z"}
2021-11-10 09:36:07
{"log":"2021/11/10 08:36:07 ERROR : rhel84.iso: Failed to copy: multipart copy: read failed: unexpected EOF\n","stream":"stdout","time":"2021-11-10T08:36:07.336968324Z"}
2021-11-10 09:36:04
{"log":"\n","stream":"stdout","time":"2021-11-10T08:36:04.332633217Z"}
2021-11-10 09:36:04
{"log":" * rhel84.iso:115% /9.435Gi, 357.260Mi/s, -\n","stream":"stdout","time":"2021-11-10T08:36:04.332617587Z"}
2021-11-10 09:36:04
{"log":"Transferring:\n","stream":"stdout","time":"2021-11-10T08:36:04.332600704Z"}
2021-11-10 09:36:04
{"log":"Elapsed time: 16m0.1s\n","stream":"stdout","time":"2021-11-10T08:36:04.332554507Z"}
2021-11-10 09:36:04
{"log":"Transferred: 0 / 1, 0%\n","stream":"stdout","time":"2021-11-10T08:36:04.332545764Z"}
2021-11-10 09:36:04
{"log":"Checks: 39 / 39, 100%\n","stream":"stdout","time":"2021-11-10T08:36:04.332537147Z"}
2021-11-10 09:36:04
{"log":"Errors: 2 (retrying may help)\n","stream":"stdout","time":"2021-11-10T08:36:04.33252774Z"}
2021-11-10 09:36:04
{"log":"Transferred: \u0009 284.221Gi / 282.744 GiByte, 101%, 243.294 MiByte/s, ETA -\n","stream":"stdout","time":"2021-11-10T08:36:04.332513493Z"}
Okay, also das ISO schlägt manchmal fehl runtergeladen zu werden.
Aber WIESO sagt es: 284.221Gi / 282.744 GiByte, 101%
- Wieso sind das so viele Daten? Das gesamte runterzuladende ISO-Verzeichnis ist gerade mal so ~15 GB groß.
- Wie kann der Download bei 101% sein?
Es ist an der Zeit, dass wir unseren eigenen Debug-Container starten, da der laufende rclone-Container zur Laufzeit nicht angenehm debugged werden kann.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: deployment-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 100Gi
---
apiVersion: v1
kind: Pod
metadata:
name: deployment-pvc
spec:
containers:
- name: deployment-pvc
image: ubuntu
command: ["sleep"]
args: ["1000000"]
volumeMounts:
- mountPath: "/mnt"
name: deployment-pvc
volumes:
- name: deployment-pvc
persistentVolumeClaim:
claimName: deployment-pvc
- Starte Debug-Pod mit genug Speicherpatz, um das ~10GB iso runterzuladen
- Installiere rclone
- Konfiguriere rclone
- Hole die laufende Konfiguration aus der Kubernetes Config-Map
- Hole die Environment-Variablen aus dem StatefulSet-Manifest
- Packe es alles an die korrekten Orte im Debug-Pod
- Starte rclone manuell, um zu schauen, ob es irgendwelche sinnvollen Error ausgibt
root@deployment-pvc:/mnt# rclone copy SRC:SRC/iso /mnt/ --config /tmp/rclone.config -v
2021/11/10 15:46:05 INFO : Local file system at /mnt/: Waiting for checks to finish
2021/11/10 15:46:06 INFO : platform-rescue-pxe/casper/initrd.lz: Copied (replaced existing)
2021/11/10 15:46:12 INFO : platform-rescue-pxe/casper/filesystem.squashfs: Multi-thread Copied (replaced existing)
2021/11/10 15:46:12 INFO : platform-rescue.iso: Multi-thread Copied (replaced existing)
2021/11/10 15:46:40 INFO : Local file system at /mnt/: Waiting for transfers to finish
2021/11/10 15:47:05 INFO :
Transferred: 9.612G / 10.678 GBytes, 90%, 164.090 MBytes/s, ETA 6s
Errors: 0
Checks: 15 / 15, 100%
Transferred: 3 / 4, 75%
Elapsed time: 59.9s
Transferring:
* rhel84.iso: 88% /9.435G, 331.554M/s, 3s
2021/11/10 15:48:05 INFO :
Transferred: 26.404G / 10.678 GBytes, 247%, 225.342 MBytes/s, ETA -
Errors: 0
Checks: 15 / 15, 100%
Transferred: 3 / 4, 75%
Elapsed time: 1m59.9s
Transferring:
* rhel84.iso:266% /9.435G, 311.514M/s, -
[...]
2021/11/10 15:54:05 INFO :
Transferred: 91.543G / 10.678 GBytes, 857%, 195.297 MBytes/s, ETA -
Errors: 0
Checks: 15 / 15, 100%
Transferred: 3 / 4, 75%
Elapsed time: 7m59.9s
Transferring:
* rhel84.iso:957% /9.435G, 233.734M/s, -
Okay, das ist nun wirklich interessant… wieso hört es nicht auf, das immer gleiche File runterzuladen… ich meine… was… es hat bereits ~90GB und 957% runtergeladen, bis ich den rclone-Prozess abgebrochen habe? o_O
Das erklärt wohl mit Sicherheit die hohe CPU-Load auf dem rclone-Sidecar.
Dann probieren wir mal, ein -v hinzuzufügen, in der Hoffnung auf mehr sinnvollen Debug-Output:
root@deployment-pvc:/mnt# rclone sync SRC:SRC/iso/rhel84.iso /mnt/ --config /tmp/rclone.config -vvvv -P
2021/11/10 16:04:55 DEBUG : rclone: Version "v1.50.2" starting with parameters ["rclone" "sync" "SRC:SRC/iso/rhel84.iso" "/mnt/" "--config" "/tmp/rclone.config" "-vvvv" "-P"]
2021/11/10 16:04:55 DEBUG : Using config file from "/tmp/rclone.config"
2021-11-10 16:04:55 DEBUG : rhel84.iso: Sizes differ (src 10130292736 vs dst 8170491480)
2021-11-10 16:04:56 DEBUG : rhel84.iso: Starting multi-thread copy with 4 parts of size 2.359G
2021-11-10 16:04:56 DEBUG : rhel84.iso: multi-thread copy: stream 4/4 (7597719552-10130292736) size 2.359G starting
2021-11-10 16:04:56 DEBUG : rhel84.iso: multi-thread copy: stream 3/4 (5065146368-7597719552) size 2.359G starting
2021-11-10 16:04:56 DEBUG : rhel84.iso: multi-thread copy: stream 2/4 (2532573184-5065146368) size 2.359G starting
2021-11-10 16:04:56 DEBUG : rhel84.iso: multi-thread copy: stream 1/4 (0-2532573184) size 2.359G starting
2021-11-10 16:05:47 DEBUG : rhel84.iso: Reopening on read failure after 2532573184 bytes: retry 1/10: unexpected EOF
2021-11-10 16:05:47 DEBUG : rhel84.iso: Reopen failed after 2532573184 bytes read: InvalidArgument: Invalid Argument
status code: 400, request id: , host id:
2021-11-10 16:05:47 DEBUG : rhel84.iso: multi-thread copy: stream 4/4 failed: multpart copy: read failed: unexpected EOF
2021-11-10 16:05:47 DEBUG : rhel84.iso: multi-thread copy: stream 1/4 failed: context canceled
2021-11-10 16:05:47 DEBUG : rhel84.iso: multi-thread copy: stream 3/4 failed: context canceled
2021-11-10 16:05:47 DEBUG : rhel84.iso: multi-thread copy: stream 2/4 failed: context canceled
2021-11-10 16:05:47 DEBUG : rhel84.iso: Received error: multpart copy: read failed: unexpected EOF - low level retry 1/10
Transferred: 10.759G / 9.435 GBytes, 114%, 188.357 MBytes/s, ETA -
Errors: 0
Checks: 0 / 0, -
Transferred: 0 / 1, 0%
Elapsed time: 58.4s
Transferring:
* rhel84.iso:114% /9.435G, 165.786M/s, -
Uh, „multi-thread copy“ klingt interessant. Offenbar versucht rclone clever zu sein, indem es große Files in kleinere Teile aufteilt und diese dann versucht parallel runterzuladen, um die Downloadzeit zu verringern.
Mooooooment…
Ich wette, das wurde implementiert mit dem Content-Range Header beim GET von den Files von unserem S3-Storage.
Nun… das ist ungünstig, da wir in der Vergangenheit öfter Probleme mit der Implementierung des Content-Range Headers und Quobyte S3 hatten. In z.B. früheren Versionen lieferte es immer das gesamte File aus, obwohl nur ein Teil angefordert wurde:
# ~620MB file requesting only the first 255 bytes
# curl -I -r 0-255 http://downloads.example.com/platform-rescue.iso
HTTP/1.1 200 OK
Content-Length: 626429952
Es sieht also so aus, als würde rclone das File in mehrere kleinere Abrufe verteilen und in der Response vermutlich nicht nur den einen Teil zurück bekommen. Beim Zusammenfügen der Aufrufe am Ende wird rclone dann verwirrt und fängt offenbar einfach wieder von vorne an und lädt noch mehr runter. Rinse and Repeat. Manchmal hat dieses Vorgehen dabei auch das gesamte bereits runtergeladene File auf der Festplatte genullt.
Es stellt sich raus, dass ich doch Glück habe heute. Ich kann „einfach“ –multi-thread-streams 1 an rclone übergeben, damit es gewzungen wird, nur einen Thread zu benutzen, was dazu führt, dass es große Files nicht aufteilt und somit nicht einzelne Teile vom S3 anfragt, sondern nur einmal das ganze File.
Hinzufügen vom Fix
Also, das Hinzufügen eines Key-Value-Parameters zum Aufruf des Commands sollte kein Problem. Schauen wir einmal in die entrypoints.sh des benutzten rclone-Docker-Images.
Okay, die entrypoint.sh führt sync.sh aus und tut das:
eval "rclone $RCLONE_CMD $SYNC_SRC $SYNC_DEST $RCLONE_OPTS $SYNC_OPTS_ALL --log-file=${LOG_FILE}"
Das ist nun etwas ungünstig, da es durch die dort benutze Variante des Shell Quotings nicht möglich macht „–multi-thread-streams 1“ in $SYNC_OPTS zu nutzen, da der Aufruf dann einfach fehlschägt aufgrund von Word Splitting.
Suchend nach weiteren Lösungen haben wir erneut Glück, denn die rclone-maintainer haben ein sehr gutes Feature eingebaut:
Every option in rclone can have its default set by environment variable.(https://rclone.org/docs/#options-1)
So, hier sind wir also nun. Ich habe 2(!) Zeilen in das Deployment Manifest hinzugefügt, um das Problem zu lösen (oder mehr oder weniger als Workaround, weil das Content-Range S3-Problem dadurch nicht behoben ist).
+ - name: RCLONE_MULTI_THREAD_STREAMS
+ value: "1"
Randnotiz: Es sieht für mich so aus, als ob das rlcone-Docker-Image einen kompletten crond aufsetzt, damit das rclone regelmäßig laufen kann mit weiterem Programmcode, damit es auto-spawned und auto-killed für mögliche falschlaufende Prozesse. Es gab bestimmt gute Gründe, das so zu bauen. Ich kann mir auch vorstellen, edass es anstatt der 300 Zeilen Bash-Code viellleicht auch diese eine Zeile getan hätte (zumindest für den Fall, wie ich das nutze)… das ist aber nur meine persönliche Meinung:
while sleep $how_often_you_want_to_run; do timeout rclone copy "${myargs[@]}" ... $timeout; done
Funny fun fun facts
Wie das Problem bereits einen Tag vorher sich anschlich
Das alles startete bereits einen Tag davor, als der Prometheus Alertmanager Alarm kam, dass die Persistent Volumes zu 100% waren aufgrund des neuen großen ISO-Files. ![]()
Einfacheres Setup?
Dieses bereits leicht verrückte Setup zusätzlich mit dem rclone-Sidecar haben wir nur implementiert, um das Orginal-Problem (damals, mit der noch älteren S3-Version) des Content-Range Headers zu umgehen. Ohne das Verhalten hätten wir das z.B. direkt so in NginX lösen können:
location / {
proxy_pass {{ .Values.config.proxy_pass }};
aws_access_key {{ .Values.config.access_key }};
aws_secret_key {{ .Values.config.secret_key }};
s3_bucket kickstartserver;
proxy_set_header Authorization $s3_auth_token;
proxy_set_header x-amz-date $aws_date;
proxy_cache s3cache;
proxy_cache_valid 200 302 24h;
}
Zusätzlich wäre selbst dieses ganz Kubernetes NginX-Setup möglicherweise nicht notwendig gewesen, wenn es aktuell möglich wäre (ohne hohen organisatorischem Aufwand), eine S3-Quobyte-Read-Only ACL so zu erstellen, das die benutzten S3 Credentials nur lesend Zugriff auf das eine einzelne Bucket bekommen könnten. Dadurch könnten wir uns vielleicht die Abstraktion von HAproxy (Octavia) → NginX (Ingress Controller) → NginX (Static-File Webserver) sparen.
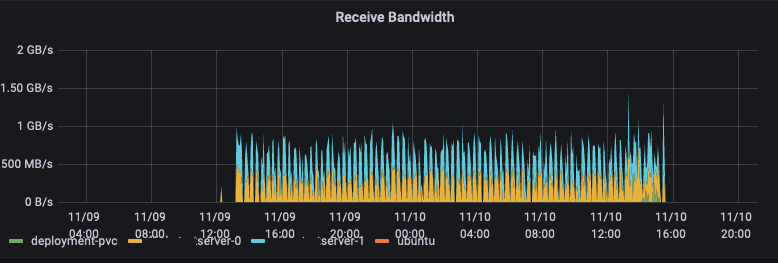
Viel Bandbreite benutzt
Da das rclone-Sidecar in 4 Pods (2 in Stage, 2 in Prod) lief und es konstant mit ca. 100-200 MB/s runtergeladen hat und wir ca. 40h dieses Verhalten hatten…
haben wir ungefähr 324 TB von dem selben 10 GB ISO-File runtergeladen.
Einige Alte und Neue Erkenntnisse
Kommen wir hier langsam zum Ende, es war ein Vergnügen und Schmerz zugleich das zu debuggen. ![]()
Manchmal ist es nicht hilfreich, viel des benutzten Stack zu verstehen. Das kann dazu führen die Problem auf Layern zu suchen, wo es gar kein Problem gibt. In dem Fall war die korrekte Fehlermeldung bereits von NginX ausgegeben worden mit „file xyz.iso was truncated“. Wenn es das sagt, könnte das auch einfach das Problem sein, wie wir oben gelernt haben.
Manchmal ist einfach besser, aber nicht immer machbar. Das kann dazu führen, dass man eine Verkettung von Kompromissen baut, die im Normalfall gut funktioniert… aber manchmal eben auch nicht.



