Eine Frage des Prozesses, nicht der Software
Wie eingangs erwähnt, stellt sich aber nicht die Herausforderung in der Wahl einer geeigneten Software. In der CI/CD zeigt sich, wie gut im Vorfeld alle Anforderungen bedacht wurden. Hier spiegelt sich als weitere Methode die Adaption des “Shift-Left-Testings” wider. In dieser Methode werden Erkenntnisse aus dem Betrieb eines Systems bereits vor dem Deployment erfasst und analysiert. Dies bedeutet zwar mehr Arbeit während der Entwicklung, aber weniger Nacharbeiten im Regelbetrieb. Und das wiederum weniger Aufwand bei Neuentwicklungen, Migrationen oder anderen Arten der Anpassung.
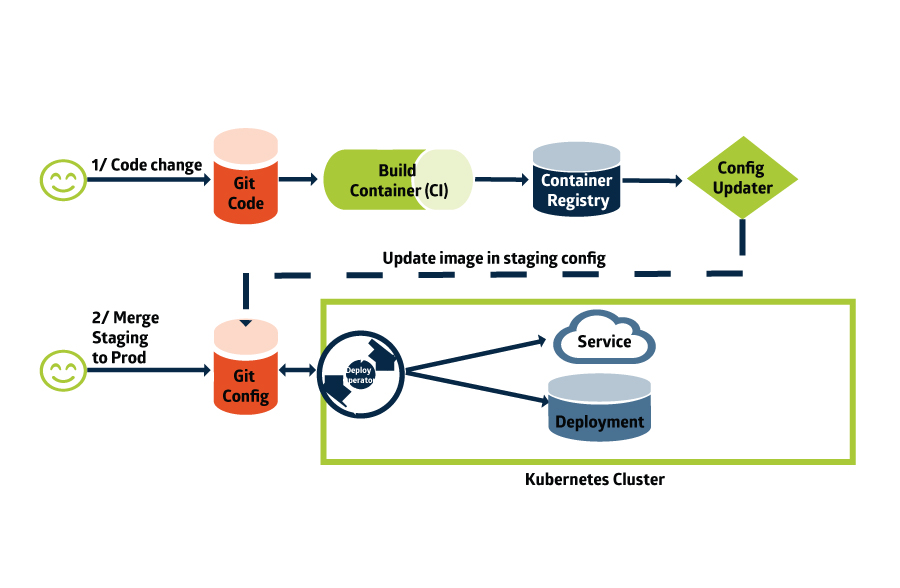
Das ist schlussendlich auch das Ziel von CI/CD. Die vielen verschiedenen Methoden und Erfahrungen sollen zusammengeführt werden und einfach anwendbar sein. Dabei sollte jede Tätigkeit automatisiert sein, um einen steten Fluss zwischen Code-Entwicklung und Betrieb zu gewährleisten. Fehler sollen vor der Installation auf produktiven Systemen erkannt und behoben werden. Jedes Element ist transparent und dokumentiert.
Wie am Ende all das zusammengeführt wird, entscheidet jedes Team für sich. Denn durch die einheitliche Nutzung von Git-Repositories, YAML-Configs und Kubernetes sind drei wichtige Pfeiler gesetzt, um einen transparenten und nachvollziehbaren Workflow für alle Nutzenden zu erstellen.
Um das meiste aus einer CI/CD herauszuholen, sind wiederum vorhergehende Standards zu etablieren. Da hilft der Themenbereich “App Definition & Image Build”, dem wir uns im nächsten Blogbeitrag widmen werden.
Wer nicht warten kann: Solltet ihr Fragen haben oder bei der Entscheidung Hilfe benötigen, helfen wir euch gern weiter. Wir haben für alle Probleme den richtigen Lösungsansatz. Schreibt uns einfach!



